理解KMP
算法的基本思想是:当出现不匹配时,就能知晓一部分文本的内容,可以利用这些信息避免将指针回退到所有这些已知的字符串之前。
KMP算法很难懂,难在它的具体代码实现十分简洁,简洁得一点都看不出其背后的思想。
所以最好先不要看代码实现,重要的是先理解思想。(注意:下面的“|”只是起辅助作用,并不存在)
ABCAB|00000
ABCAB|D
设想匹配上面一段字符串,我们已经发现第六个字符不匹配,按程序思维来讲,我们可能这次不匹配下次直接向右移动一位继续比较,这是最朴素的想法。
AB|CAB00000
A|BCABD
但是观察一下我们会发现,既然前面前几个字符已经比较过了,那我们其实可以利用这一点来多移动几位。就像下面:
ABCAB|00000
AB|CABD
其实这就是KMP算法的思想,很简单不是吗?
KMP算法中的next数组
到现主要问题是,匹配串的相同前后缀长度。
- “A"的前缀和后缀都为空集,匹配串最大长度为0;
- “AB"的前缀为[A],后缀为[B],匹配串最大长度为0;
- “ABC"的前缀为[A, AB],后缀为[C, BC],匹配串最大长度0;
- “ABCA"的前缀为[A, AB, ABC],后缀为[A, CA, BCA],匹配串最大长度为1;
- “ABCAB"的前缀为[A, AB, ABC, ABCA],后缀为[B, AB, CAB, BCAB],匹配串最大长度为2;
在讲next数组时,你应该看过教科书或者算法实现,我猜你一定会有些困惑。别怕这篇文章就是要帮你解决这些问题。
其实观察上面,思路已经比较清晰了。
我们定义两个变量i 和 matchLength,其中 i 控制循环,matchLength记录匹配长度。
如果前后缀相同的话,那就在next数组中保存matchLength加一之后的值,再继续检查下一位。一旦发现一位不匹配,那matchLength立即回退到零。
void getNext(char* p,int next[]){
int i,matchLength;
int pLen = strlen(p);
next[0] = 0;
while (i < pLen){
//p[matchLength]表示前缀,p[i]表示后缀
if (matchLength == -1 || p[i] == p[matchLength]){
++i;
++matchLength;
next[i] = matchLength;
}else{
// next数组加长一位,matchLength回退到0
matchLength = next[matchLength];
}
}
}
KMP本质
kmp的本质其实就是有限状态机(DFA)。
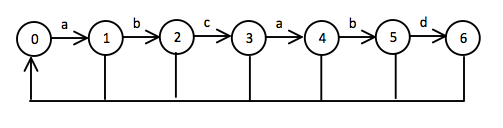
最初在状态0,然后每次输入新的字符,都会转移到新的状态或者保持旧状态。
评价
在实际应用中,它比暴力算法的优势并不十分明显,因为极少有应用程序需要在重复性很高的文本中查找重复性很高的模式。但该方法的一个优点是不需要再输入中回退。这使得KMP字符串查找算法更适合在长度不确定的输入流(例如标准输入)中查找进行查找,需要回退的算法在这种情况下则需要复杂的缓冲机制。——《算法(第四版)》
未完待续