不相交集合有两种基本操作:合并(union)和查询(find)。
并查集保持了一组不相交的动态集合,每个集合通过一个代表来识别,代表即集合中的某个成员。
数组实现Quick Find
我们可以直接用数组来存储集合的标识,这样查找操作直接返回对应数组的值即可,复杂度为O(1);而合并操作每次都需要遍历整个数组,复杂度为O(n)。
0 1 2 3 4 5 6 7 8 9
-------------------------------------
id 0 1 2 3 4 5 6 7 8 9
union(1, 4)
union(1, 5)
0 1 2 3 4 5 6 7 8 9
-------------------------------------
id 0 1 2 3 1 1 6 7 8 9
有根树表示 Quick Union
为了降低合并操作的复杂度,我们可以用多个有根树表示集合,每个结点存储指向其父亲结点的指针,根节点指向自己。判断是否属于同一个集合时,我们只需要判断元素所属的树根是否相同。
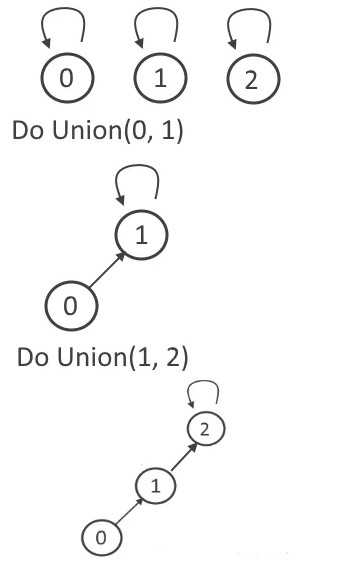
这种方式实际上并没有本质提高,而且如果一些极端情况下会退化成一个链表,查找操作的复杂度反而上升了,上面的例子中就是这样。
查找和合并的时间复杂度都为O(h),h表示树高。
所以我们需要对合并操作进行优化,优化方式一般为以下两种。
按秩合并(union by rank)
秩(Rank)就是一颗树的结点数,即使包含较少结点的树根指向包含较多结点的树根。
所以上面的例子中union(1, 2)操作会让 2 节点会指向 1 。
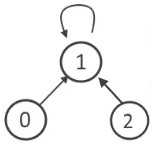
这样查找操作最坏情况的时间复杂度为O(logN)。
路径压缩
在查找所在位置是我们会进行递归,那么我们可以利用递归回溯的过程进行路径压缩。所谓压缩表示的就是将从x结点搜索到祖先结点所经过的结点都指向该树的根节点结点。
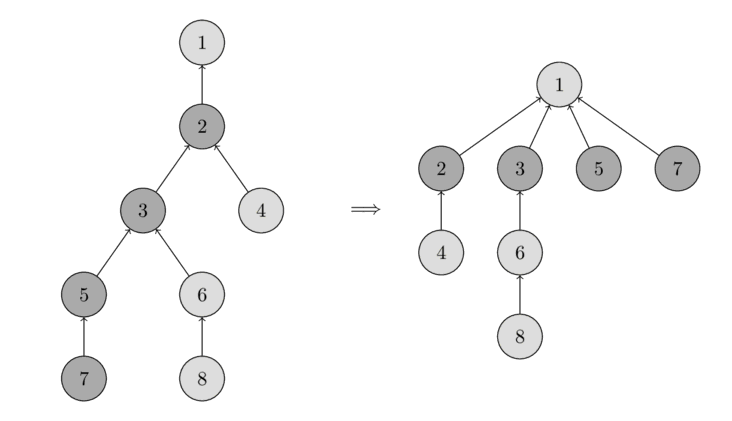
在压缩之后树的高度低了,所以查找复杂度也降低了。
同时使用按秩合并和路径压缩
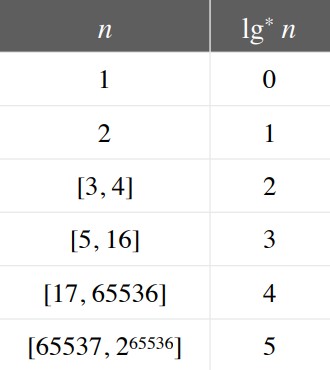
复杂度为反阿克曼函数,具体的证明比较复杂,可以参科下面这篇讲义。
这里简单介绍下阿克曼函数,他表示f(n) = 2 ^2^2^…^2,可见其增长速度极快,其反函数用lg*n表示,其值可以认为小于5。
https://www.cs.princeton.edu/~wayne/kleinberg-tardos/pdf/UnionFind.pdf
 参考文章:
https://cp-algorithms.com/data_structures/disjoint_set_union.html
https://algs4.cs.princeton.edu/15uf/
参考文章:
https://cp-algorithms.com/data_structures/disjoint_set_union.html
https://algs4.cs.princeton.edu/15uf/