
为何要使用协程
- 单线程环境中的并发:一些编程语言/环境只有一个线程。这时如果需要并发,协程是唯一的选择。(注意JS规范没有事件循环)
- 简化代码:可以避免回调地狱
- 有效利用操作系统资源和硬件:协程相比线程,占用资源更少,上下文更快
何为协程
协程是具有以下功能的函数:
- 可以暂停执行(暂停的表达式称为暂停点);
- 可以从挂起点恢复(保留其原始参数和局部变量)。
在JS中协程是一种用function*语法标记的生成器函数,函数内部可以使用yield关键字暂停自身。然后可以通过发送一个值来恢复它。发送的值将显示为的返回值,yield执行将继续直到下一个yield。注意JS生成器并不是一个真正的协程,我们可以称之为浅协程
进程、线程和协程的比较
进程:变量隔离,自动切换运行上下文 线程:不变量隔离,自动切换运行上下文切换 协程:不变量隔离,不自动切换运行上下文切换
将协程视为轻量级线程是协程的最直观,最高级的隐喻。与实际线程相比,最大的概念差异是缺少调度程序(所有上下文切换必须由程序完成)
简易协程封装
每次你使用协程你总会做以下三件事。
- 调用函数然后返回作为结果的协程对象
- 调用协程对象上的next方法,执行到第一个yield
- 然后你能做的就是next(),运行协程并发送值给他
我们能把所有功能包装到一个函数中:
function coroutine(f) {
var o = f(); // instantiate the coroutine
o.next(); // execute until the first yield
return function(x) {
o.next(x);
}
}
使用这个函数,我们之前的例子变成下面形式:
var test = coroutine(function*() {
console.log('Hello!');
var x = yield;
console.log('First I got: ' + x);
var y = yield;
console.log('Then I got: ' + y);
});
// prints 'Hello!'
test('a dog'); // prints 'First I got: a dog'
test('a cat'); // prints 'Then I got: a cat
Stackful coroutines
首先,让我们看看什么是有栈协程,他如何工作,并且如何作为一个库实现。可能它比较容易解释,因为他构成和线程相似。 Fibers 或是有栈协程是一个处理函数调用的展开的栈。为了更准确的阐述这种协程的工作方式,我们将从底层的视角简要了解函数的栈帧和调用。那就让我们先来看看 Fibers 的特性。
- 每个fiber拥有独立的栈
- fiber的生命周期独立于调用它的代码
- fiber能从进程中分离出来并加到另一个进程中
- 不能同时运行在一个进程中
所提及属性的含义如下:
- fiber的上下文切换必须由用户操作,而不是OS(OS依然可以通过剥夺其所在进程来剥夺fiber)
- 在同一个进程中的两个fiber之间,不会出现真正的数据竞争,因为只有其一处于活动状态
- fiber中的I/O操作应为异步,从而其他的fiber可以依次无阻塞的运行
现在,从对函数调用堆栈所做的解释开始,详细解释fiber的工作原理。
栈是内存的连续块,用于存储局部变量和函数参数。 但是,更重要的是,在每个函数调用之后(除少数例外情况),其他信息都会放入栈中,以使被调用函数知道如何返回被调用方并恢复处理器寄存器。
一些寄存器具有特殊用途,并在函数调用时保存在栈中。这些寄存器(在ARM体系结构的情况下)为:
- SP – stack pointer
- LR – link register
- PC – program counter
栈指针SP是一个寄存器,用于保存属于当前函数调用的堆栈起始地址。由于有了这个值,可以很容易地引用保存在栈中的参数和局部变量。 在函数调用期间,链接寄存器LR非常重要。它存储了当前函数执行结束后将要执行的代码的返回地址(到被调用方的地址)。调用该函数时,PC被保存到LR。当函数返回时,使用LR恢复PC。 程序计数器PC是当前执行指令的地址。
每次调用函数时,都会保存链接寄存器,以便该函数知道完成后要返回的位置。
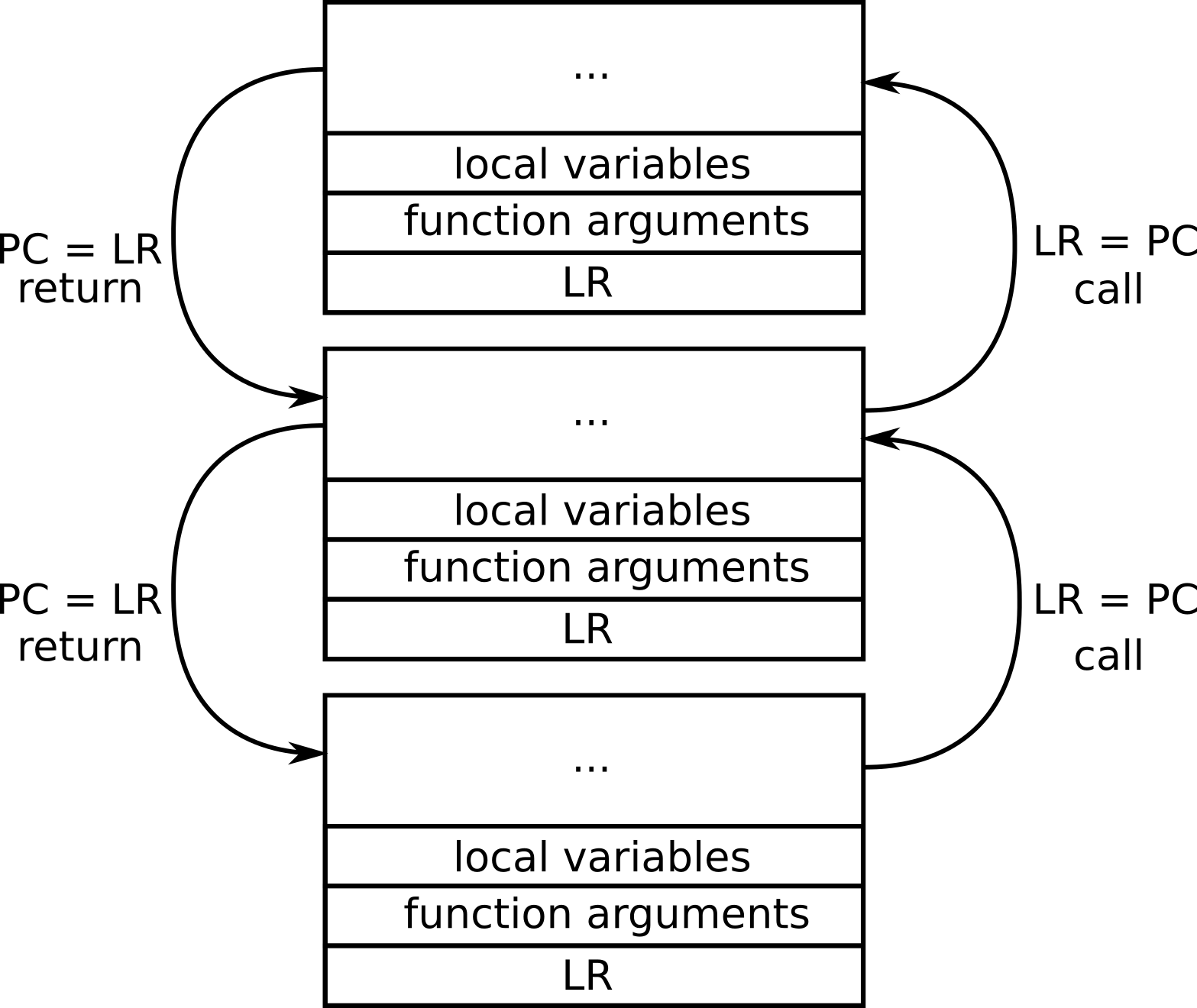
当栈式协程被执行时,被调用函数使用先前分配的栈来存储其参数和局部变量。因为所有信息都存储在栈式协程中调用的每个函数的堆栈中,所以fiber可能会在协程中调用的任何函数中暂停执行。
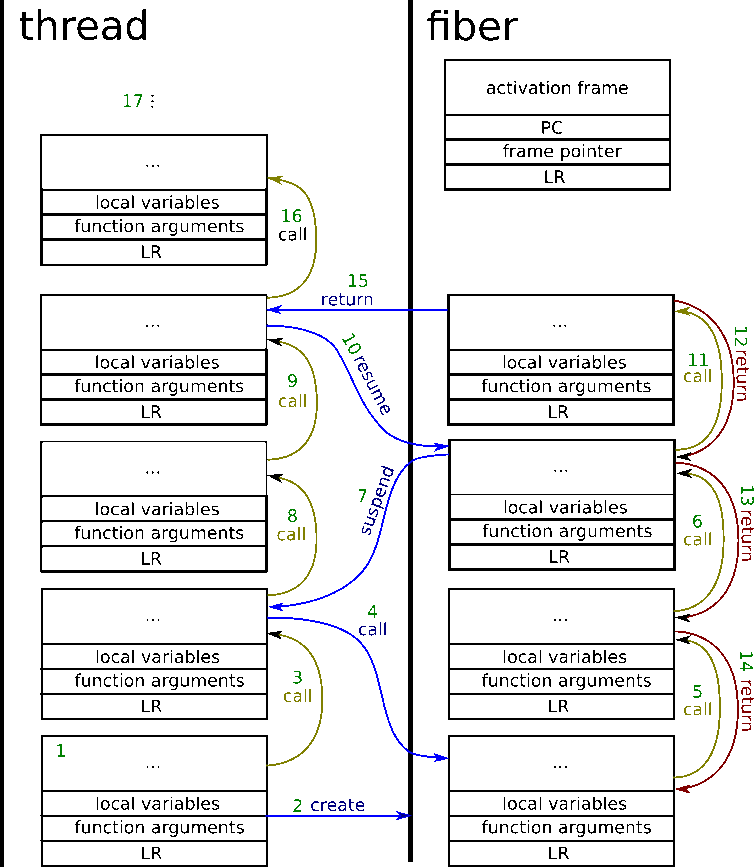
现在,让我们来看看上面的图片中发生了什么。首先,线程和fiber有自己独立的栈。绿色数字是操作发生的顺序号。
- 线程内部的常规函数调用,在栈上进行分配。
- 该函数创建fiber对象。最终分配了fiber的栈。创建fiber并不一定意味着它会立即执行。 同样,激活帧被分配。激活帧中的数据是以这种方式设置的,即将其上下文保存到处理器的寄存器中将导致上下文切换到fiber的栈。
- 常规函数调用
- 调用协程,处理器的寄存器设置为激活帧的内容。 5,6. 协程内部的常规函数调用
- 恢复协程–在协程调用期间发生类似的事情。激活帧会记住协程内部的处理器寄存器状态,该状态是在协程暂停期间设置的。
Stackless coroutines
在无堆栈协程的情况下,无需分配整个堆栈。它们消耗的内存少得多,但是因此存在一些限制。
首先,如果它们不为堆栈分配内存,那么它们如何工作?在有协程的情况下,要存储在栈上的所有数据都放在哪里? 答案是:在程序调用栈上。
无栈协程的秘密在于,它们只能从顶级函数中挂起自己。对于所有其他函数,它们的数据都分配在被调用栈上,因此从协程调用的所有函数必须在挂起协程之前完成。协程保留其状态所需的所有数据均在堆上动态分配。这通常需要几个局部变量和参数,其大小远小于预先分配的整个堆栈。
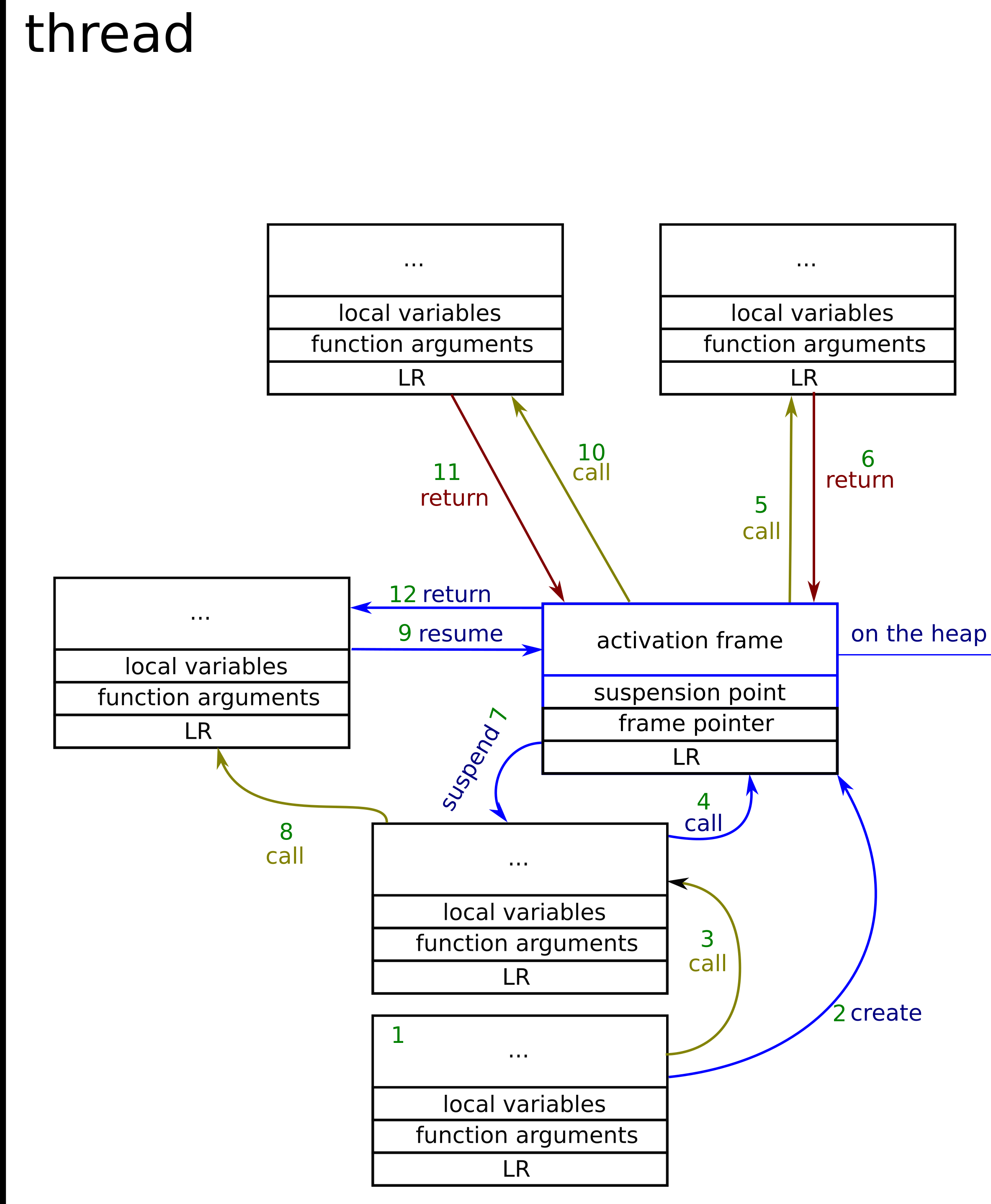
现在我们可以看到,只有一个栈。让我们一步一步地跟踪图片中发生的事情。 (协程激活帧有两种颜色–黑色是存储在栈中的颜色,蓝色是存储在堆中的颜色)。
- 常规函数调用,该帧存储在堆栈中
- 该函数创建协程。这意味着将激活帧分配到堆上的某个位置。
- 常规函数调用。
- 协程调用。协程的主体在通常的栈上分配。并且程序流程与常规函数的情况相同。
- 从协程调用常规函数。同样,一切仍在栈中。 (注意:协程目前无法暂停,因为它不是协程的顶层函数)
- 函数返回到协程的顶级函数(注意,协程现在可以暂停自身)
- 协程挂起–将需要在整个协程调用中保留的所有数据放入激活帧。
- 常规函数调用
- 协程恢复–这是通过常规函数调用发生的,但是会跳到先前的挂起点+从激活帧恢复变量状态。
栈式协程 vs 无栈协程
能够从子函数产生的协程实现称为栈式,即它们可以记住整个调用栈。协程的其他实现(只能从协程函数的顶层执行)只能是无堆栈的。JavaScript 实现就是无栈式的(Python,C#和Kotlin也是如此)。
协程是无限制的协作式多任务任务:在协程内部,任何函数都可以挂起整个协程(函数激活本身,函数调用方的激活,调用方的调用方的激活等)。但是JS只能直接从生成器内部挂起生成器,而只有当前函数激活被挂起。由于这些限制,生成器有时被称为浅协程。
在下面的示例中,我们创建一个生成器,生成一个?,然后调用forEach将其传递给匿名函数的数组it => { ... }。由于匿名函数调用仍然算作子函数,因此我们无法yield从内部进行调用。此示例在运行时失败,但是在编译语言中,这将导致编译错误。
function* createGenerator() {
console.log(yield "?");
[1, 2, 3].forEach(it => {
console.log(yield it); // runtime error
});
}
const c = createGenerator();
console.log(c.next("A"));
console.log(c.next("B"));
console.log(c.next("C"));
用如下方式避免使用回调函数:
function* genFunc() {
for (const x of ['a', 'b']) {
yield x; // OK
}
}
参考文章: https://blog.panicsoftware.com/coroutines-introduction/ https://dkandalov.github.io/yielding-generators https://x.st/javascript-coroutines https://exploringjs.com/es6/ch_generators.html#ch_generators_ref_3